spark背景
Spark是一个基于内存计算的开源的集群计算系统,目的是让数据分析更加快速,主要源自于MapReduce迭代式计算,交互式数据挖掘
Spark与Hadoop的对比
- Spark的中间数据放到内存中,对于迭代运算效率更高。
- Spark更适合于迭代运算比较多的ML和DM运算。因为在Spark里面,有RDD的抽象概念
- Spark比Hadoop更通用。
- Spark提供的数据集操作类型有很多种,不像Hadoop只提供了Map和Reduce两种操作。比如map, filter, flatMap, sample, groupByKey, reduceByKey, union,
join, cogroup, mapValues, sort,partionBy等多种操作类型,Spark把这些操作称为Transformations。同时还提供Count, collect, reduce, lookup, save等多种actions操作。
什么是spark
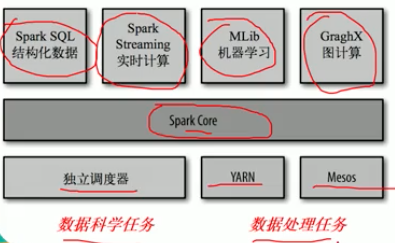
SparkCore:将分布式数据抽象为弹性分布式数据集(RDD),实现了应用任务调度、RPC、序列化和压缩,并为运行在其上的上层组件提供API。
SparkSQL:Spark Sql 是Spark来操作结构化数据的程序包,可以让我使用SQL语句的方式来查询数据,Spark支持 多种数据源,包含Hive表,parquest以及JSON等内容。
SparkStreaming: 是Spark提供的实时数据进行流式计算的组件。
MLlib:提供常用机器学习算法的实现库。
GraphX:提供一个分布式图计算框架,能高效进行图计算。
BlinkDB:用于在海量数据上进行交互式SQL的近似查询引擎。
Tachyon:以内存为中心高容错的的分布式文件系统。