spark安装
- local
- on yarn(on yarn模式就是将资源管理交给hadoop的yarn,自己本身只做计算与任务调度)
- standalone(自己的资源管理与调度器)
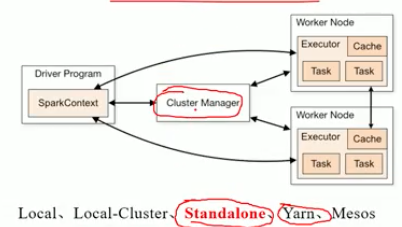
standalone模式安装
构建一个由Master+Slave构成的Spark集群,Spark运行在集群中。所有安装都必须要保证安装的环境一致,否则成功只能看运气
环境 系统:Centos6.10;3台虚拟机 软件:JDK1.8 + Spark2.4.4
1 | | Host | HostName | Master | Slave | |
虚拟机:
启动无窗口VirtualBox虚拟机 以便用远程桌面连接
虚拟机配置eth2网卡,开机不能自动获取ip
集群机器环境初始化
集群部署需要节点间互信才能启动所有节点的 Worker,互信的意思就是无需输入密码,只根据 hostname 就可以登录到其他节点上,遍历3个节点都进行配置
创建hadoop用户
使用hadoop单独用户操作数据,安全
1 | # 创建hadoop用户 |
修改主机名
spark配置文件中配置的是机器名
修改主机名(临时):sudo hostname server01
修改主机名(永久)
1 | [root@server01 ~]# cat /etc/sysconfig/network |
修改/ect/hosts文件
spark是根据域名来查找slave节点的,域名解析,所以需要单独配置hosts文件
1 | 100.80.128.253 server02 |
安装ssh, 配置开机启动,root远程访问
1 | yum install openssh-server -y |
配置ssh互信
1 | // 生成公钥 |
关闭防火墙
spark的启动会开放一些端口(8080,4040),并且机器远程访问需要ssh(22),所以需要关闭防火墙
1 | # 默认清空表中所有链的内容 |
安装jdk8
安装spark
解压拷贝
1 | tar -zxvf spark-2.4.4-bin-hadoop2.7.tgz |
修改slaves配置文件
server01将会是master,所以只配置这两个
1 | server02 |
修改spark-env.sh配置文件
1 | # java环境变量 |
启动
启动集群
1 | server01机器启动节点 |
使用
指定master,这样会使用spark集群./bin/spark-shell --master spark://100.80.128.177:7077
不指定,则使用本机器spark./bin/spark-shell
1 | [hadoop@server02 spark-2.4.4-bin-hadoop2.7]$ ./bin/spark-shell |