如何打开gc日志
go version
go version go1.13.1 linux/amd64
gc日志解释
手动gc
debug.FreeOSMemory() vs runtime.GC()
通过pprof
疑问
- gc后内存是否归还
- 不要频繁调用gc
goroutine发生panic,只有自身能够recover,其它goroutine是抓不到的
1 | package test |
如上是不能捕获到异常的,需要如下处理在协程中捕获
1 | package test |
https://www.zhihu.com/question/54997169
客户端怎么感知leader切换?
最简单的方法非leader收到请求回复客户端自己不是leader
raft成员变更
raft里最麻烦的应该是成员变更,简单点就一个个加,实现起来有些麻烦,启动时还得从快照和日志里捞成员
raft集群节点与允许故障个数:
Raft 协议是一个分布式共识(consensus)算法, 可以参考 ATC-Raft 和 Thesis-Raft 这两篇文章. 两篇文章是同一个作者, 第一篇是小论文, 第二篇是大论文, 阐释地更加全面、详细
任何领导人对于给定的任期号,都拥有了之前任期的所有被提交的日志条目.
前提是:领导人都必须存储所有已经提交的日志条目
拒绝掉那些日志没有自己新的投票请求。最后一条日志条目的索引值和任期号定义谁的日志比较新。如果两份日志最后的条目的任期号不同,那么任期号大的日志更加新。如果两份日志最后的条目任期号相同,那么日志比较长的那个就更加新。通过选举策略实现
Raft算法保证所有已提交的日志条目都是持久化的,只要一条记录被复制到大多数机器上,领导人就能提交.
领导人宕机会有如下几种情况:
保存到大多数服务器上时已经提交后宕机保存到大多数服务器但是还没来得及提交时宕机还没有将日志记录保存到大多数服务器上时宕机对于2,3情况,日志被覆盖并没有什么问题,但是对于1,日志被覆盖就会丢数据出现问题.如下展示了一种情况,一条已经被存储到大多数节点上的老日志条目,也依然有可能会被未来的领导人覆盖掉
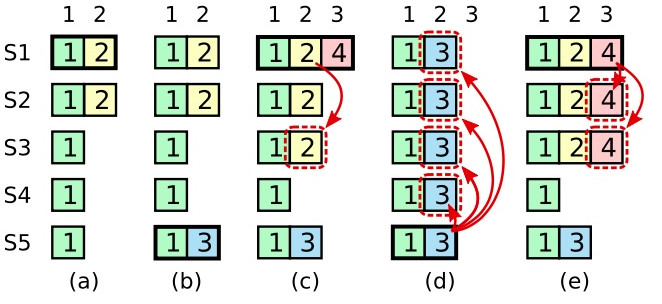
所以综上,领导人无法决定是否对老任期号的日志条目进行提交.Raft为了简化问题使用一种更加保守的方法,引入任期号的概念
保留之前的任期号),然后本任期内产生的日志的任期号都会加1(这不是存在多数据的问题?)反证法是“间接证明法”一类,是从反方向证明的证明方法,即:肯定题设而否定结论,经过推理导出矛盾,从而证明原命题; 接下来通过反证法来证明领导人的完全特性(任何领导人对于给定的任期号,都拥有了之前任期的所有被提交的日志条目)
假设任期 T 的领导人(领导人 T)在任期内提交了一条日志条目,但是这条日志条目没有被存储到未来某个任期的领导人的日志中(假设大于T的最小任期U的领导人U没有这条日志条目)
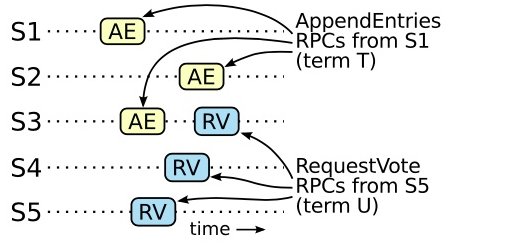
图9: S1,S2,S3,S4,S5是5台机器,如果 S1 (任期 T 的领导者)提交了一条新的日志在它的任期里,然后 S5 在之后的任期 U 里被选举为领导人,然后至少会有一个机器,如 S3,既拥有来自 S1 的日志,也给 S5 投票了。
同时接受了来自领导人T 的日志条目,并且给领导人U 投票了,如图 9这个投票者是产生这个矛盾的关键。无限的重试幂等的,所以这样重试不会造成任何问题领导人选举是 Raft 中对时间要求最为关键的方面。Raft 可以选举并维持一个稳定的领导人,只要系统满足下面的时间要求:
广播时间(broadcastTime) << 选举超时时间(electionTimeout) << 平均故障间隔时间(MTBF)
集群节点变更是很常见的需求,例如移除故障或者增加节点,首先来思考这个过程中会遇到什么问题?

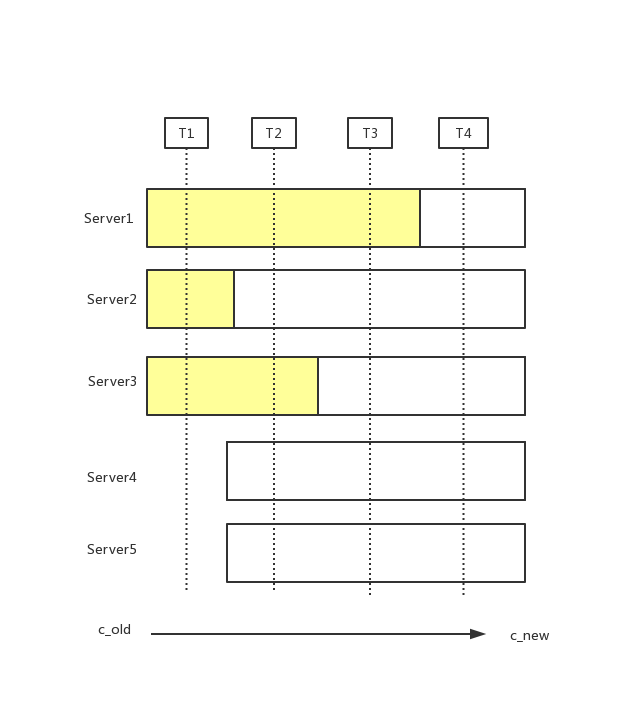
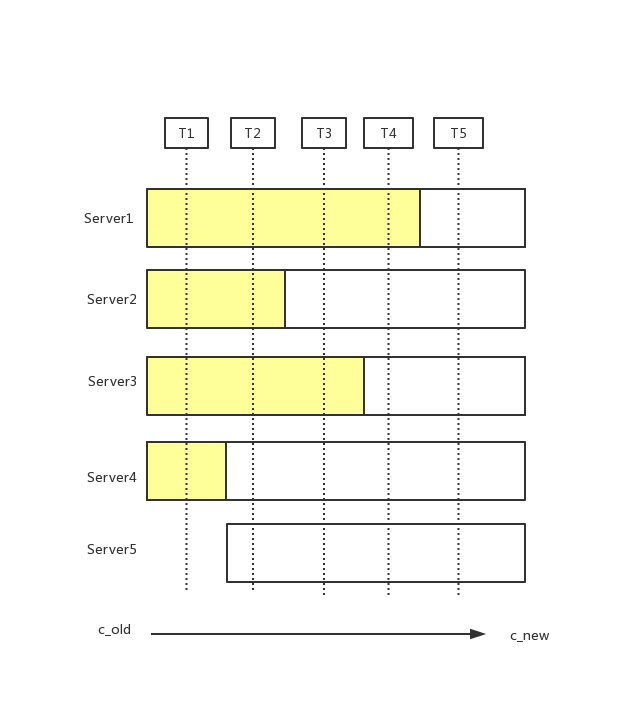
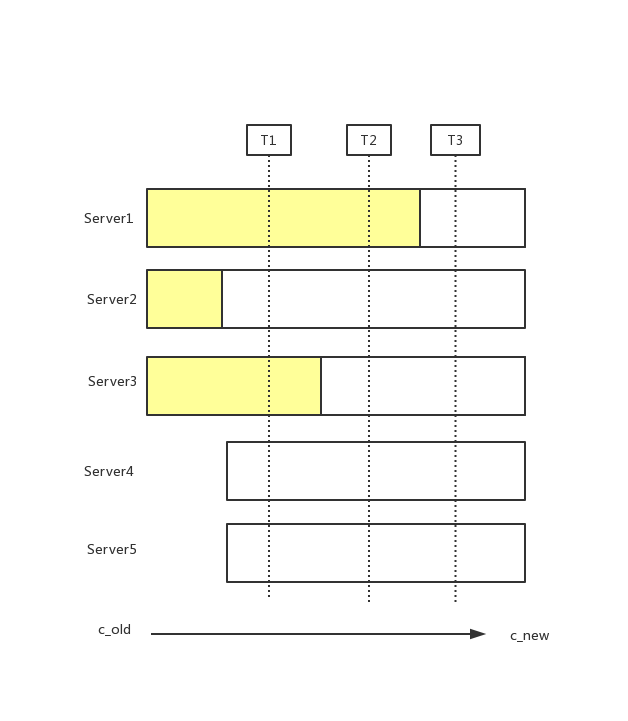
这里把[server1,server2,server3] 叫做c_old,[server1,server2,server3,server4,server5] 叫做c_new
集群从c_old状态变成c_new状态,在不停c_old服务情况下,会有一个节点同时给c_old集群中的发送变更消息,通知server更新自己的配置,由于分布式服务,各个server应用通知存在时间差,就会存在如上图情况.
存在这样的一个时间点,两个不同的领导人在同一个任期里都可以被选举成功。一个是通过旧的配置,一个通过新的配置,例如server5通过server3,server4,server5投票选举成leader,3个选票超过新配置总数5的一半, server1 通过server1,server2投票选举成leader,2个选票超过老配置3的一半
分布式情况中协调多个节点进行同一操作,最容易想到的最简单的就是2PC(两阶段提交),但这样其实是有问题的,先不说 2 PC 一些 corner case 需要处理,整个过程还可能会导致暂时的服务不可用,虽然这个时间在多数情况下面可能比较短
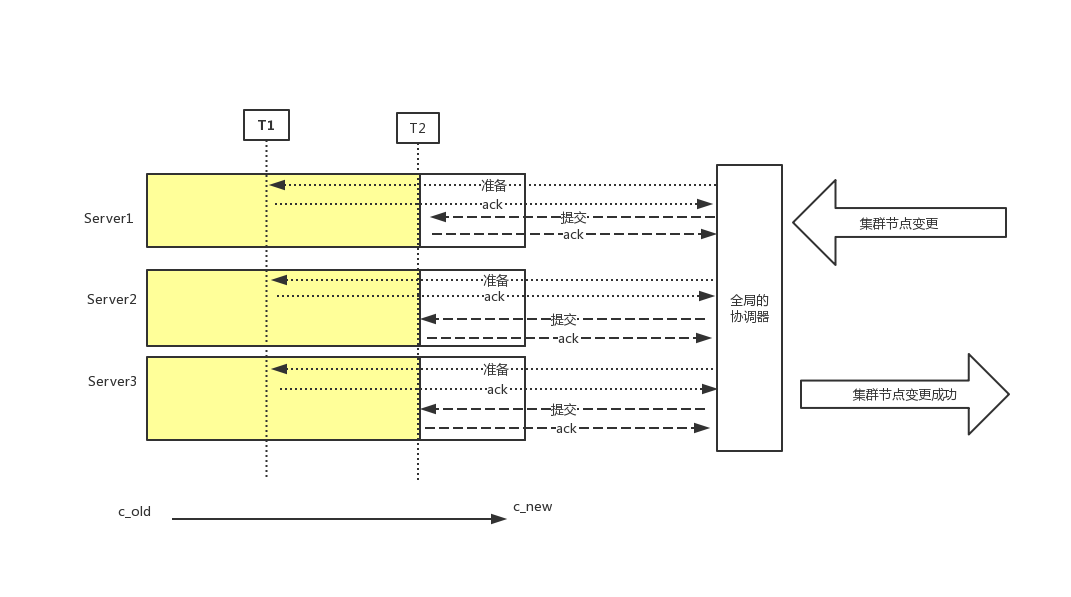
T1阶段各个server收到节点变更消息(各个server)
raft采用如下规则来解决上面问题:
来分析下是如何实现的
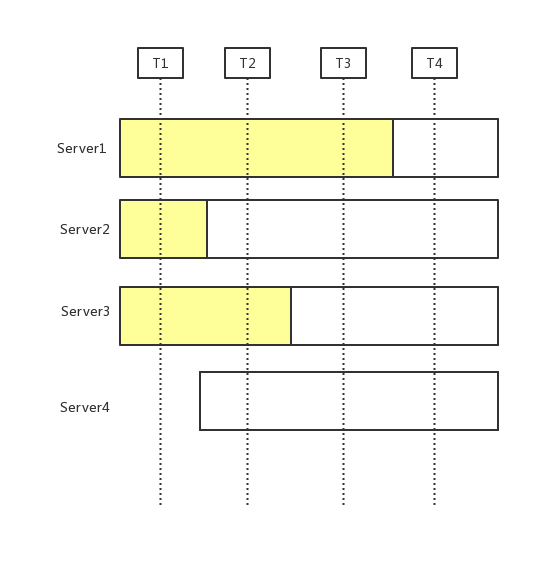
T1时刻, 省略
T2时刻,
https://www.jianshu.com/p/99562bfec5c2
https://zhuanlan.zhihu.com/p/56215322
https://zhuanlan.zhihu.com/p/27908888
https://zhuanlan.zhihu.com/p/25344714
集群节点表更,最复杂的情况,从A,B,C变成C,D,E
共同决定的过程
https://doc.rust-lang.org/rust-by-example/hello/print.html
https://www.rust-lang.org/learn
1 | :b : 二进制格式 |
切片
1 | package main |
1 | package append_vs_copy |