pprof工具使用
pprof
1 | heap profile: 13: 764144560 [139616: 4600982112] @ heap/1048576 |
764144560-258760704-207003648-165601280-54255616-43401216-34717696-196608-163840-18432-16384-8192-896-48=0
http://xxxx:8888/debug/pprof/heap?debug=1
1 | # runtime.MemStats |
结果分析:
sys
Sys 是下面列出的 XSys 字段的综合。Sys 维护着为 Go 运行时预留的虚拟内存空间地址,里面包含了:堆、栈,以及其他内部数据结构。
1 | Sys(72373071) = HeapSys(65994752)+ GCSys(2394112) + OtherSys(991083) + BuckHashSys(1616868)+ StackSys(1114112) + MSpanSys(196608) + MCacheSys(65536) |
HeapSys: 从操作系统获得的堆内存大小,虚拟内存空间为堆保留的大小,包括还没有被使用的
StackSys: 从操作系统取得的栈内存大小
MSpanSys: 从操作系统为mspan获取的内存字节数
MCacheSys: 从操作系统为mcache获取的内存字节数
BuckHashSys: 在profiling bucket hash tables中的内存字节数
GCSys: 垃圾回收元数据使用的内存字节数
OtherSys: off-heap的杂项内存字节数.
HeapSys
HeapSys:程序向应用程序申请的内存
HeapAlloc:堆上目前分配的内存
HeapIdle:堆上目前没有使用的内存
HeapReleased:回收到操作系统的内存
- HeapSys == HeapIdle + HeapInuse 代表了作为堆用途的内存空间。堆内存以Span为单元进行管理,从Span中分配内存给对象,分为Idle(没有分配对象)和Inuse(有对象)两种类型。
- HeapAlloc == Alloc 代表了堆上的未回收对象的实际占用空间(包括可回收部分)。注意,这和HeapInuse是有区别的。HeapInuse代表了分配对象的Span的大小,而HeapAlloc代表了实际对象的大小,因此可以认为一个是粗统计,一个是细统计,HeapAlloc <= HeapInuse
- StackSys 代表协程栈大小,其实是Stack Span的大小,可以和Idle Span互相转换。不同版本Go语言的最小协程栈大小是不同的,这次问题里面的协程栈大小为8K,因此30万协程2.4G,和图中的Stack部分相符,但还不足以解释剩下6G的堆内存占用量。
命令行pprof命令
查看30秒钟的CPU状态信息(执行后会卡30s,等就行了)
1 | go tool pprof http://localhost:6060/debug/pprof/profile |
查看堆状态信息
1 | go tool pprof http://localhost:6060/debug/pprof/heap |
-source 命令配置源码地址[可以定位到具体的代码行]
top,list 等常用命令
https://cloud.tencent.com/developer/section/1143647
https://www.dazhuanlan.com/2019/09/29/5d907f1435d79/
https://colobu.com/2019/08/28/go-memory-leak-i-dont-think-so
Go字符串的内存布局
https://blog.csdn.net/pplin/article/details/70241075
https://draveness.me/golang/datastructure/golang-string.html
MapReduce
Hadoop MapReduce 源于 Google 在2004年12月份发表的 MapReduce 论文。Hadoop MapReduce 其实就是 Google MapReduce 的一个克隆版本
MapReduce 入门
MapReduce是一种编程模型,其思想来自于函数式编程,和Python,Lisp语言中的map和reduce函数类似,用于大规模数据集的分布式运算
python map函数
1 | >>>def square(x) : # 计算平方数 |
1 | >>>def add(x, y) : # 两数相加 |
MapReduce进阶
MapReduce工作过程
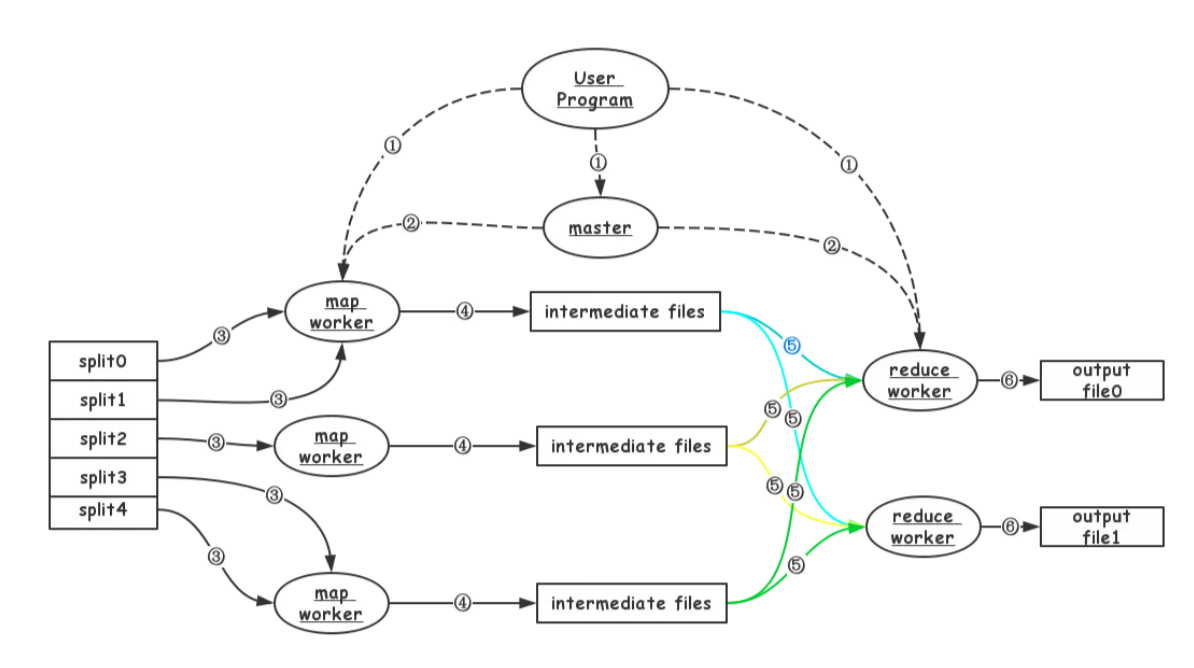
- MapReduce框架对输入的文件数据分成M片,每份数据的大小为16~64MB(可由用户配置)。
- 在多台机器上开始运行User Program:包括一个master、多个map worker和多个reduce worker。
- master主要负责map worker和reduce worker的状态管理和任务分发。
- map worker从GFS读取分配到的文件数据,并进行相应的处理。MapReduce框架的调度会尽量使map worker运行的机器与数据靠近,以提高数据传输的效率。所以,数据传输可以是本地,也可能是网络。
- map worker的输出缓存在内存中,并定期刷到本地磁盘上。这些中间数据的位置信息会通过心跳信息告诉master,master记下这些信息后,通知reduce worker。数据存储在本地。
- reduce worker通过RPC从map worker读取需要的中间数据。数据通过网络传输。
- reduce worker对中间数据进行“合并”处理后,输出结果。
容灾
MapReduce 如何容灾是其最重要的部分,对于故障我们可以分为 worker故障和master故障,worker故障又可以分为 map worker和reduce worker。
Worker故障
Master 通过心跳的机制来检测worker故障
- map worker
- map任务执行完成后宕机:因为中间数据存储在本地磁盘,需要重新执行。
- map任务执行完成前宕机:需要重新执行
- reduce worker
- reduce任务执行完成后宕机:因为数据存储在GFS,不需要重新执行
- reduce任务执行完成前宕机:需要重新执行,输出文件可以覆盖原来的(文件名一样)
Master故障
master宕机,任务失败,可以简单的通过周期写快照的方式来处理master故障
优化
- 局部性:MapReduce用于大数据集的处理,其主要瓶颈是网络带宽。通过优化调度,可以让执行MapReduce任务的机器尽可能靠近机器。(同一机器==>同一机架==>同一机房…)
- 任务粒度:执行MapReduce任务的过程其实就是M个Map任务+R个Reduce任务。M和R必须比机器数大很多才会有利于负载均衡
- 备份任务:当MapReduce任务即将执行完成时,MapReduce框架会针对那些还在执行的任务,启动一个对应的备份任务。之后,只要主任务或备份任务执行完成,MapReduce任务就完成了。这样可以有效避免整个MapReduce任务被少部分比较慢的机器拖死
mapReduce试用范围
- 要想使用mapreduce首先要确保输入可以相对独立的进行计算(map),数据之间没有计算依赖关系
疑问
一个mapreduce中,reduce是否需要等待所有mapper执行后才执行?
需要,在 mapper 结束之前,reducer 很难知道属于一个 key 的数据是否收集完整,因此如果过早地开始 reduce,无法保值结果的正确性如果一个mapper执行特别慢会拖慢整个任务(长尾现象)
为了应对长尾现象(一个特别慢的子任务拖慢整个任务),MapReduce提供了 Backup Task的机制:当一个MapReduce接近结束时,master 对还处理 in-progress状态的task额外的调度备份执行,当primary和backup中一个执行成功就标记成功。Mapreduce中Map与Reduce任务的个数如何确定
Mapreduce中Map与Reduce任务的个数
参考
Google-MapReduce中文版
Google-MapReduc
论文笔记:MapReduce
MapReduce论文笔记
MapReduce之Shuffle过程详述
https://blog.csdn.net/zhanglh046/article/details/78360762
https://github.com/feixiao/Distributed-Systems
Hadoop的MapReduce
Hadoop的MapReduce是对MapReduce的工程实践,做了大量的优化
- MapReduce中排序发生在哪几个阶段??这些排序是否可以避免,为什么??
一个MapReduce作业由Map阶段和Reduce阶段两部分组成,这两阶段会对数据排序,
- Map Task会在本地磁盘输出一个按照key排序(采用的是快速排序)的文件( 实际上Map阶段的排序就是为了减轻Reduce端排序负载)
- 在Reduce阶段,每个Reduce Task会对收到的数据排序,
- 如何排序,用什么排序算法
defer
defer
https://studygolang.com/articles/12136
go 的 defer 语句是用来延迟执行函数的,而且延迟发生在调用函数 return 之后,defer 的重要用途一:清理释放资源,defer 的重要用途二:执行 recover
Golang捕获panic堆栈信息的优雅姿势