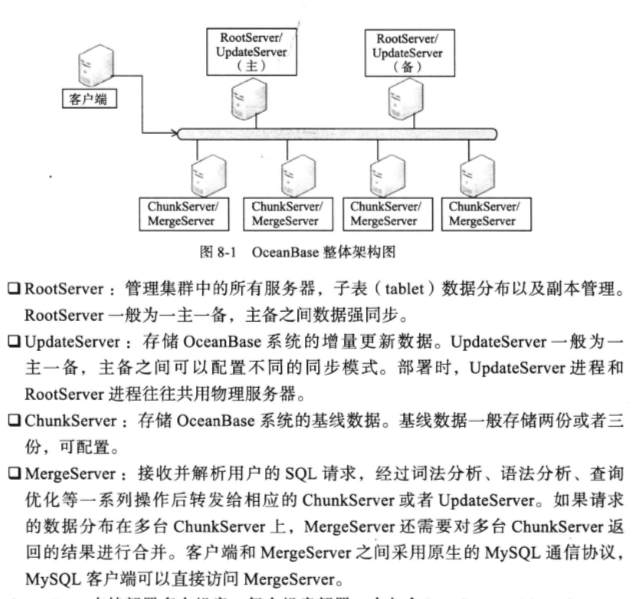
分布式存储引擎层包含三个模块: RootServer,UpdateServer,ChunkServer
- RootServer: 用于整体控制,实现子表分布,副本复制,负载均衡,机器管理以及Schema管理
- UpdateServer: 用于存储增量数据
- ChunkServer: 用于存储基线数据
分布式存储引擎层包含三个模块: RootServer,UpdateServer,ChunkServer
支持强一致性和跨行跨表事务,支持服务器线性扩展
定期合并与数据分发:
查询结果 = 旧子表+ 冻结内存表+新的活跃内存表
= 新子表+ 新的活跃内存表
如何实现强一致性:
1. 操作日志同步到主备的情况下才能够返回客户端写入成功
2. 为了提高可用性,如果主机往备机同步操作日志失败,比如备机故障,主机可以将备机从同步列表中剔除,本地跟新成功后就返回客户端写入成功.
OceanBase数据分为基线数据和增量数据两部分,基线数据分布在多台ChunkServer上,增量数据全部放在一台UpdateServer上.
用户的读写请求,都发给MergeServer,
Paxos选举协议以及两阶段提交
理解一致性可以从两个角度:用户/存储系统
客户端:
读写(Read-your-writes)一致性: 如果客户端A写入了最新的值,那么A的后续操作都会读取到最新的值,但是其他用户可能要过一会儿才能看到
会话(session)一致性: 要求客户端和存储系统交互的整个会话期间保证读写一致性,如果原有会话因为某种原因失效,会话之间的操作要回滚掉
单调读一致性: 如果客户端A已经读取了对象的某个值,那么后续操作将不会读取到更早的值
单调写一致性: 客户端A的写操作按顺序我拿成,这意味着对与同一个客户端的操作,存储系统的多副本也要按照与客户端相同的顺序完成
从存储系统角度看:
分布式系统区别于传统单机系统在于能够数据分布到多个节点,并在多个节点之间实现负载均衡.
数据分布方式主要有两种:
- 哈希分布,如一致性哈希
- 顺序分布
衡量机器负载设计很多因素:如机器load,cpu,内存,磁盘以及网络等资源,分布式存储需要能够自动识别负载高的节点,当某台机器负载高时,实现自动迁移
传统哈希分布,当服务器上下线时,N值发生变化,数据映射完全被打乱.几乎所有数据需要重新分布,这将带来大量的数据迁移
一致性哈希有点在于节点加入/删除是只会影响到在哈希环中相邻的节点,而对其他节点没影响
将大表顺序划分为连续的范围,每个范围称为一个子表,总控服务器负责将这些子表按照一定的策略分配到存储节点上.
主副本将写请求复制到其他备副本,最常见的做法是同步操作日志,主副本确定操作的顺序并写入到日志中复制给其他副本
复制协议分为两种:
基于复制协议,要求任何时刻只能有一个副本为主副本,由它来确定写操作之间的顺序.如果主副本故障,需要选举一个备副本成为新的主副本,这步操作称为选举,经典的选举协议为(Paxos协议)
CAP理论: 一致性(Consistency),可用性(Availability)以及分区可容忍性(Tolerance of network Partition)三者不能同时满足.
最大可用性模型: 正常情况下强同步模式,异常情况切换为异步复制模式
故障检测往往通过租约协议
故障检测最自然想到的是心跳机制,但还是存在问题(没有收到心跳包并不一定能100分确认发生故障并停止了服务)
传统心跳机制存在问题在于: 机器A和机器B之间需要对“机器B是否应为被认为发生故障且停止服务”达成一致.
租约机制就是带有超时时间的一种授权,假设机器A需要检测机器B是否发生故障,机器A可以给机器B发放租约,机器B持有的租约的有效期范围内才允许提供服务,否则主动停止复制.机器B的租约快到期时向A重新申请租约来延长有效期.
增加提前量,假设B机器租约有效期是10s,A机器必须啊哟加一个提前量,比如11s,才能任务机器B的租约过期.
常见分布式存储系统分为两种结构:单层结构/双层结构.
通过数据分布,复制以及容错等机制,能够将分布式存储系统部署到成千上万台服务器
总控节点一般用于维护数据分布信息,执行工作机管理,数据定位,故障检测与恢复,负载均衡等全局调度工作,那么总控节点是否会成为性能瓶颈呢?
不太可能,而且可以通过一些手段来避免
两阶段提交协议:
A组织B,C,D三人去爬长城,如果所有人同意去爬长城,那么活动将举行,如果有一个人不同意去爬长城,则活动取消.
但是
两阶段提交协议是阻塞协议,执行过程需要锁住其他更新,且不能容错
单机存储引擎就是hash表,b树等数据结构在机械磁盘,ssd等持久化上的实现
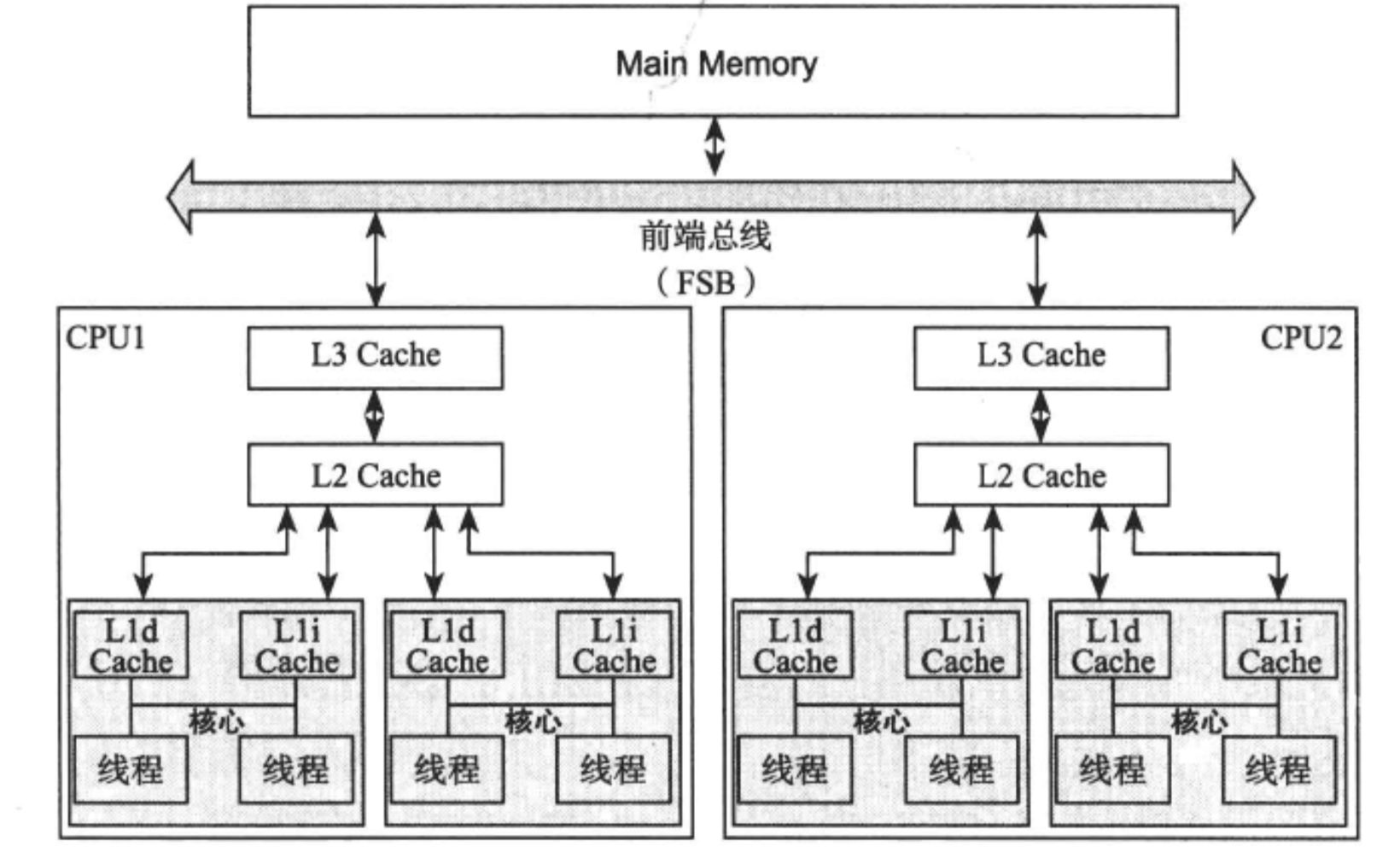
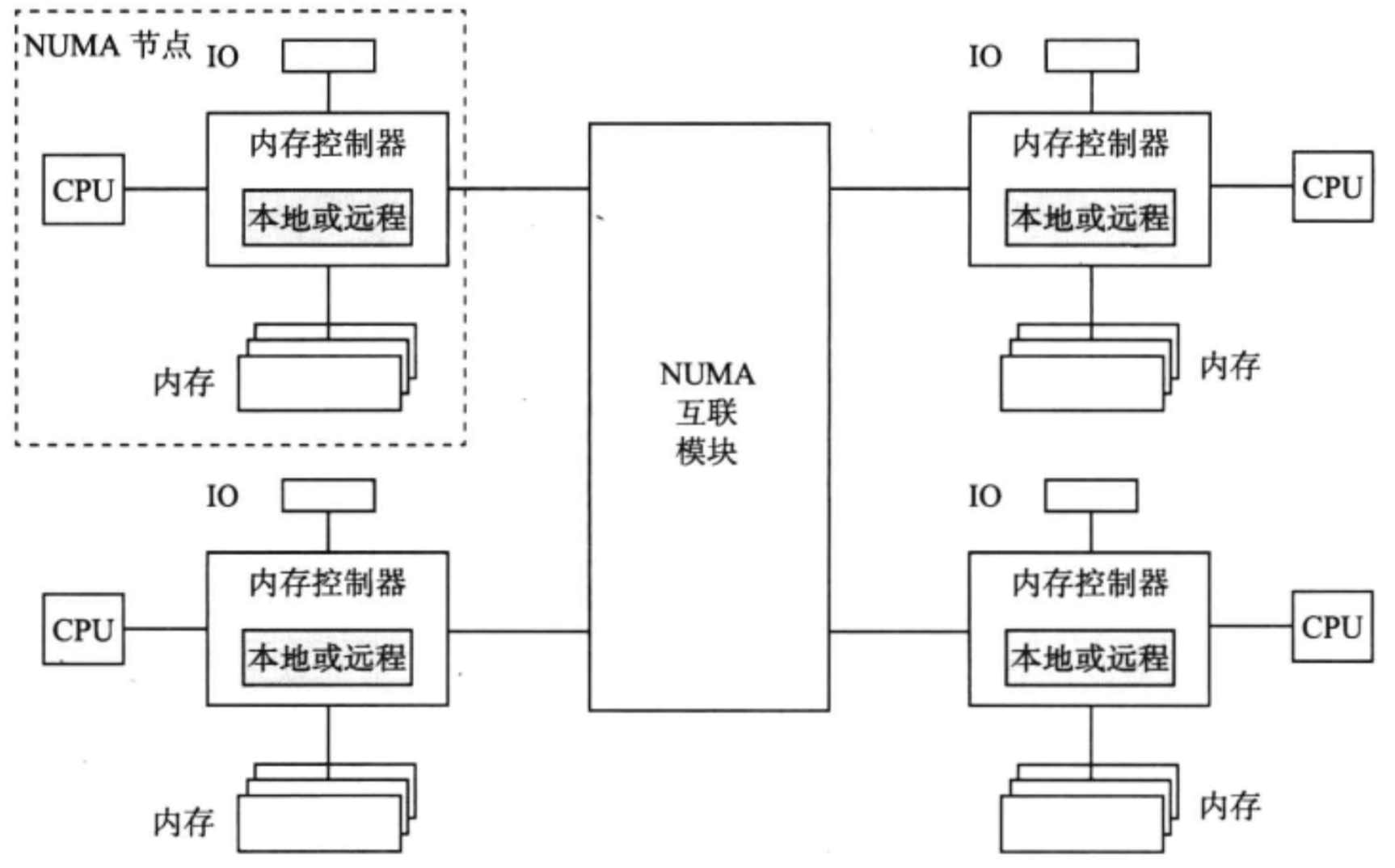
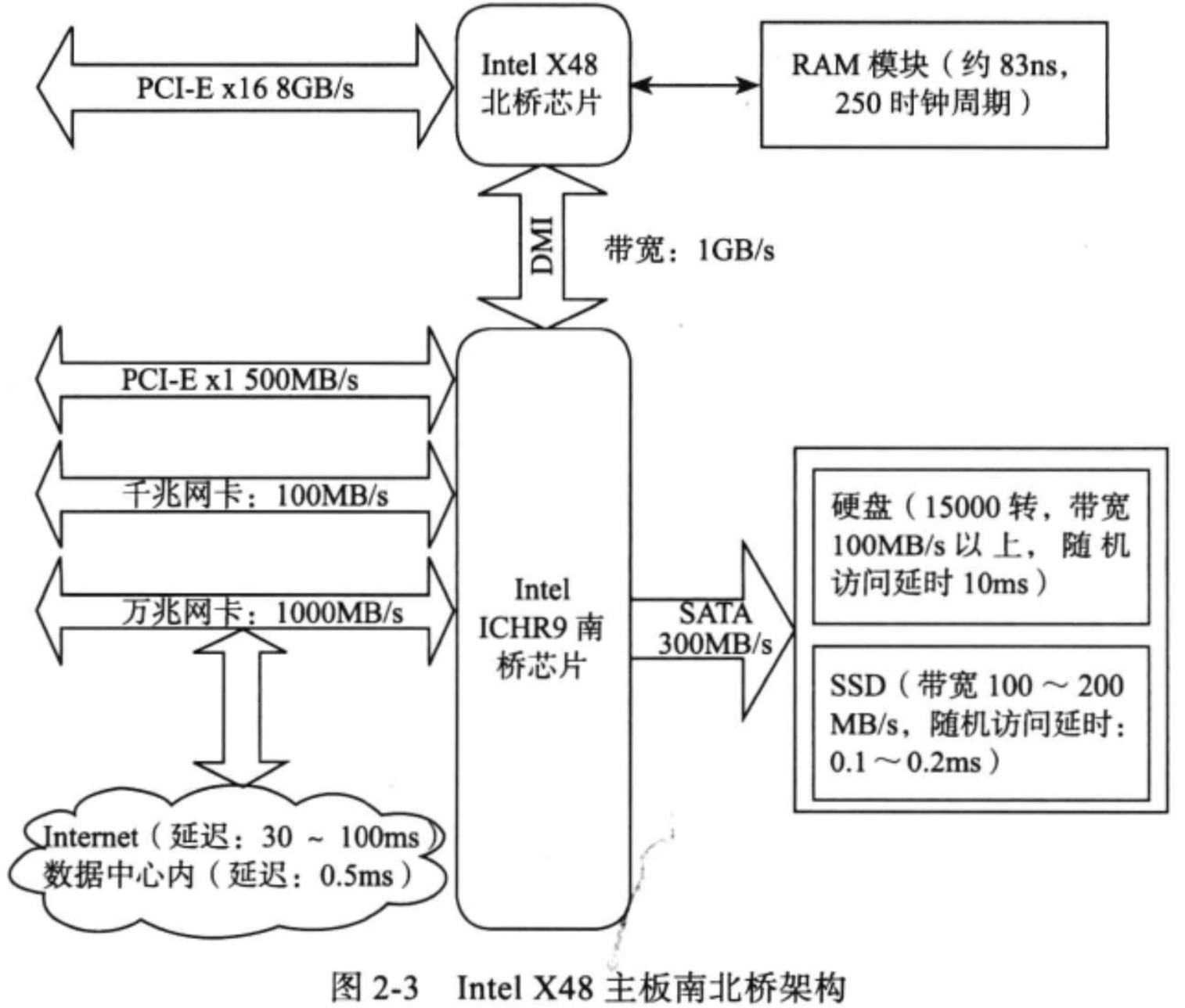
硬件性能对比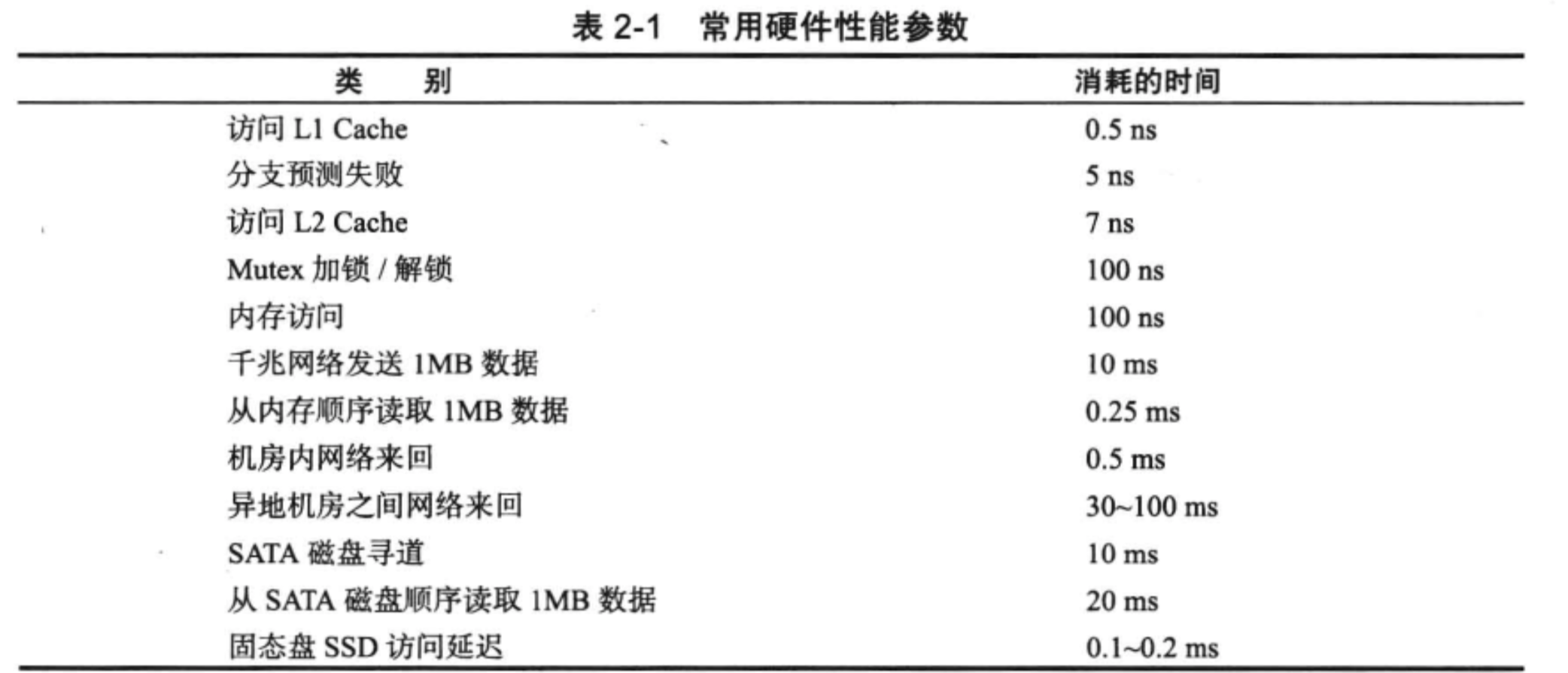
15000 转的stata盘顺序读取带宽可达到100MB以上,由于磁盘寻到的时间大约是10ms,顺序读取1Mb数据时间为: 磁盘寻道时间+ 数据读取时间,即 10ms+ 1MB/100MB/s X1000 = 20ms
存储介质对比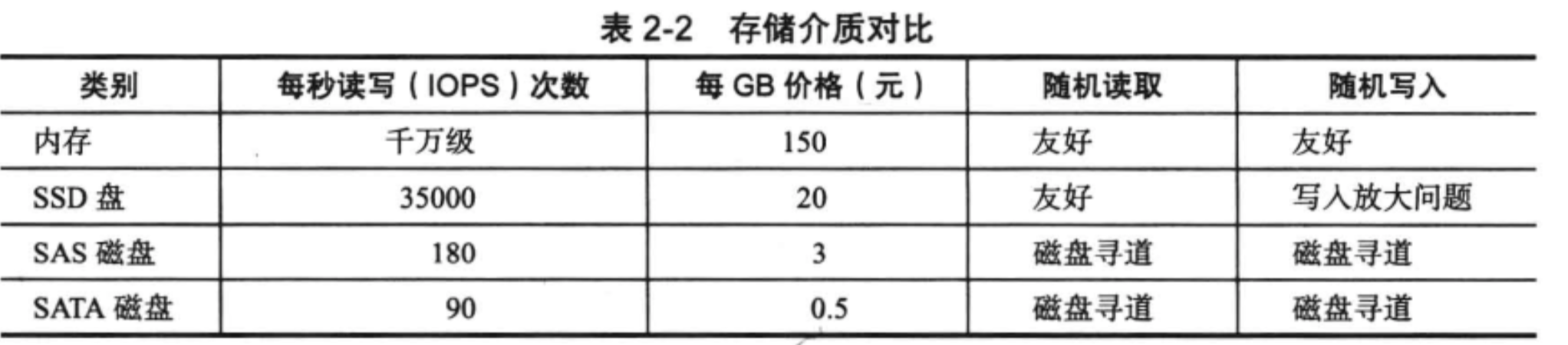
热数据(访问频繁)存储到ssd中,冷数据(访问不频繁的)存储到磁盘中
哈希表的持久化实现,支持增删读改操作,以及随机读取操作,但不支持顺序扫描,对应的存储系统为键值(key-Value)存储系统
B树的持久化实现,不仅支持单条记录的增删读改操作,还支持顺序扫描,对应的存储系统是关系数据库,当然键值系统也可以通过B树存储引擎实现
LSM树存储引擎和b树存储引擎一样,支持增、删、改、随机读以及顺序扫描.它通过批量转储技术规避磁盘随机写入问题
主要是实现 mapreduce/common_map.go 中的 doMap() 函数以及 mapreduce/common_reduce.go 中的 doReduce() 函数
疑问:
1 | func doMap( |
1 | func doReduce( |
最后在终端输入 go test -run Sequential进行测试,如果出现
1 | $ cd 6.824 |
注释掉 master_rpc.go的48行 debug("RegistrationServer: accept error", err) 即可
实现main/wc.go 中的mapF() and reduceF() 方法,统计单词出现次数
1 | func mapF(filename string, contents string) []mapreduce.KeyValue { |
1 | func reduceF(key string, values []string) string { |
运行:
1 | cd 6.824 |
文案翻译:
您当前的实现只能一次运行一个任务。 Map / Reduce最大的卖点之一是,它可以自动并行化普通的顺序代码,而无需开发人员进行任何额外的工作。 在本部分的实验中,您将完成一个MapReduce版本,该版本将工作划分为一组在多个内核上并行运行的工作线程。 虽然不像实际的Map / Reduce部署那样分布在多台计算机上,但是您的实现将使用RPC来模拟分布式计算。
mapreduce / master.go中的代码完成了管理MapReduce作业的大部分工作。 我们还在mapreduce / worker.go中为您提供了工作线程的完整代码,并在mapreduce / common_rpc.go中为您提供了处理RPC的一些代码。
您的工作是在mapreduce / schedule.go中实现schedule()。 Master在MapReduce作业期间两次调用schedule(),一次在Map阶段,一次在Reduce阶段。 schedule()的工作是将任务分发给可用的worker。 通常tasks数超过worker数,因此schedule()必须给每个工作线程一系列任务, schedule()应等待所有任务完成,然后返回。
schedule()从registerChan中获取空闲的worker的地址,然后将任务非配给空闲的worker执行.
schedule()通过Worker.DoTaskRPC发送给worder来通知worker执行任务。 该RPC的参数由DoTaskArgs在mapreduce / common_rpc.go中定义。 File元素仅由Map任务使用,是要读取的文件的名称; schedule()可以在mapFiles中找到这些文件名。
使用mapreduce / common_rpc.go中的call()函数将RPC发送给工作程序。 第一个参数是worker的地址,从registerChan读取。 第二个参数应为Worker.DoTask。 第三个参数应为DoTaskArgs结构,最后一个参数应为nil。
使用go test -run TestParallel来测试您的解决方案。 这将执行两个测试,TestParallelBasic和TestParallelCheck; 后者验证您的scheduler程序执行task的并行度
思路:
1 | func schedule(jobName string, mapFiles []string, nReduce int, phase jobPhase, registerChan chan string) { |
参考:
Go官方库RPC开发指南
Package rpc
谈谈 Golang 中的 Data Race
sync.Mutex 互斥锁
Golang中WaitGroup使用的一点坑
schedule调度的任务可能会发生错误,需要将发生错误的任务在一个空闲的worker上重新执行。这里可以对发生错误的任务使用递归的方式在一个新的worker执行。
1 | func schedule(jobName string, mapFiles []string, nReduce int, phase jobPhase, registerChan chan string) { |
倒排索引
1 | func mapF(document string, value string) (res []mapreduce.KeyValue) { |
RDD,全称为 Resilient Distributed Datasets,弹性分部署数据集,是为了对用户操作的简化,以面向对象的方式提供了RDD很多方法,rdd是懒执行的,分为转换和行动两部分
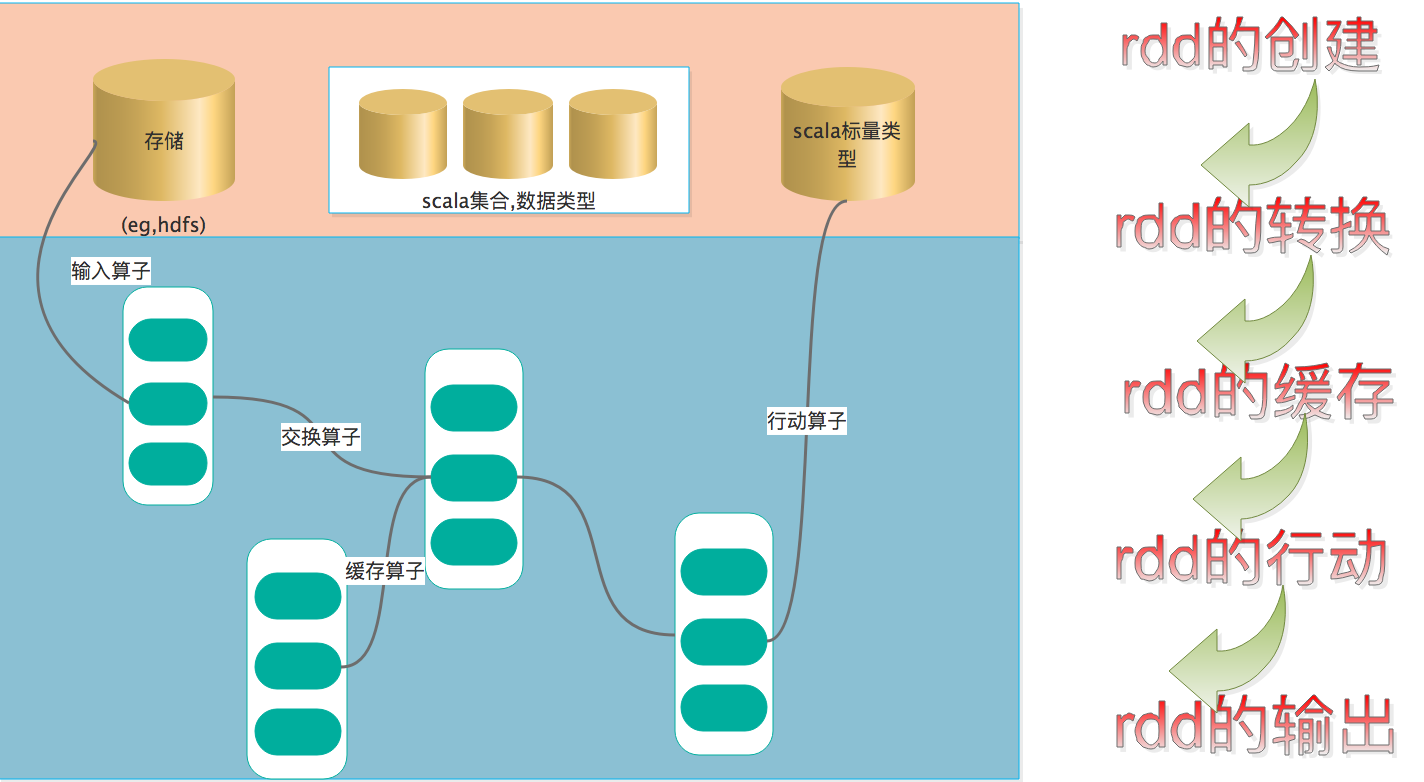
rdd创建方式分为3种:
从集合中创建
在Driver(驱动程序)中一个已经存在的集合(数组)上创建,SparkContext对象代表到Spark集群的连接,可以用来创建RDD、广播变量和累加器。可以复制集合的对象创建一个支持并行操作的分布式数据集(ParallelCollectionRDD)。一旦该RDD创建完成,分布数据集可以支持并行操作,比如在该集合上调用Reduce将数组的元素相加。
1 | scala> sc.makeRDD(0 to 10) |
环境: CentOS release 6.10 + zookeeper-3.4.14
特别注意防火墙问题
1 | tar -zxvf zookeeper-3.4.14.tar.gz |
1 | cp zoo_sample.cfg zoo.cfg |
myid文件必须在dataDir目录下
1 | mkdir /home/hadoop/zookeeper-3.4.14/tmp |
1 | cd /home/hadoop/zookeeper-3.4.14 |
并不用1 | # zkServer.sh start |
Zookeep启动正常,却报错:Error contacting service. It is probably not running
# 确认进程是否启动
[hadoop@server02 zookeeper-3.4.14]$ jps
3216 QuorumPeerMain
3303 Jps
[hadoop@server02 zookeeper-3.4.14]$ netstat -tunlp|grep 3216
# 确认端口是否开放
(Not all processes could be identified, non-owned process info
will not be shown, you would have to be root to see it all.)
tcp 0 0 :::2181 :::* LISTEN 3216/java
tcp 0 0 :::2888 :::* LISTEN 3216/java
tcp 0 0 :::43919 :::* LISTEN 3216/java
tcp 0 0 :::3888 :::* LISTEN 3216/java
# 确认防火墙是否关闭
[hadoop@server01 zookeeper-3.4.14]$ telnet server02 3888
Trying 100.80.128.165...
Connected to server02.HDFS是Hadoop的数据储存部分,主要由NameNode,DataNode,SecondNameNode组成