环境准备
- CentOS release 6.10
- hadoop2.8.0
- java-1.8.0-openjdk-devel-1.8.0.232.b09-1.el6_10.x86_64
节点部署图: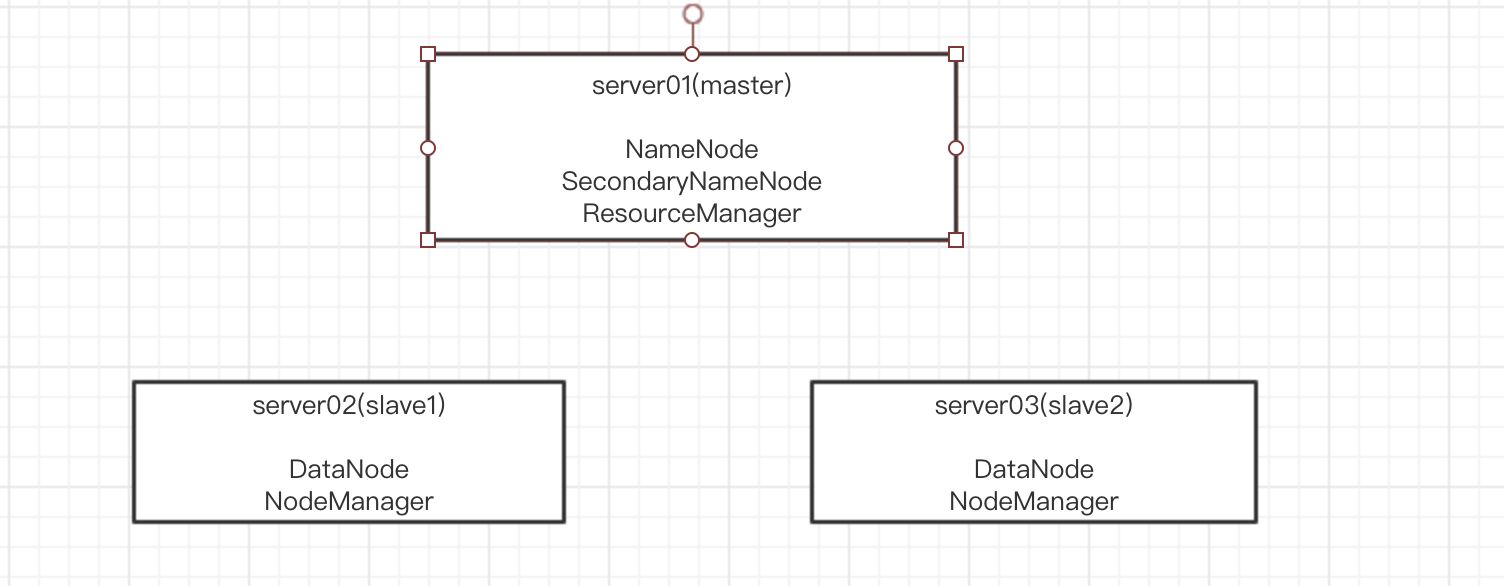
配置环境变量
/etc/profile
1 | export HADOOP_HOME=/home/hadoop/hadoop-2.8.0 |
节点部署图:
/etc/profile
1 | export HADOOP_HOME=/home/hadoop/hadoop-2.8.0 |
配置网卡ifcfg-eth2
虚拟机配置eth2网卡,每次虚拟机重启不能自动获取ip,所以如下操作
1 | /etc/sysconfig/network-scripts |
1 | yum -y install NetworkManager |
Spark是一个基于内存计算的开源的集群计算系统,目的是让数据分析更加快速,主要源自于MapReduce迭代式计算,交互式数据挖掘
Spark与Hadoop的对比
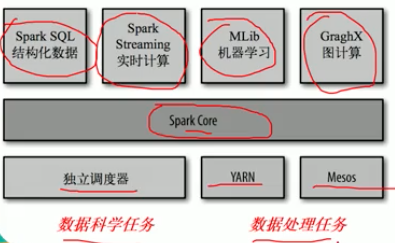
SparkCore:将分布式数据抽象为弹性分布式数据集(RDD),实现了应用任务调度、RPC、序列化和压缩,并为运行在其上的上层组件提供API。
SparkSQL:Spark Sql 是Spark来操作结构化数据的程序包,可以让我使用SQL语句的方式来查询数据,Spark支持 多种数据源,包含Hive表,parquest以及JSON等内容。
SparkStreaming: 是Spark提供的实时数据进行流式计算的组件。
MLlib:提供常用机器学习算法的实现库。
GraphX:提供一个分布式图计算框架,能高效进行图计算。
BlinkDB:用于在海量数据上进行交互式SQL的近似查询引擎。
Tachyon:以内存为中心高容错的的分布式文件系统。
构建一个由Master+Slave构成的Spark集群,Spark运行在集群中。所有安装都必须要保证安装的环境一致,否则成功只能看运气
环境 系统:Centos6.10;3台虚拟机 软件:JDK1.8 + Spark2.4.4
1 | | Host | HostName | Master | Slave | |
虚拟机:
启动无窗口VirtualBox虚拟机 以便用远程桌面连接
虚拟机配置eth2网卡,开机不能自动获取ip
集群部署需要节点间互信才能启动所有节点的 Worker,互信的意思就是无需输入密码,只根据 hostname 就可以登录到其他节点上,遍历3个节点都进行配置
使用hadoop单独用户操作数据,安全
1 | # 创建hadoop用户 |
spark配置文件中配置的是机器名
修改主机名(临时):sudo hostname server01
修改主机名(永久)
1 | [root@server01 ~]# cat /etc/sysconfig/network |
spark是根据域名来查找slave节点的,域名解析,所以需要单独配置hosts文件
1 | 100.80.128.253 server02 |
1 | yum install openssh-server -y |
1 | // 生成公钥 |
spark的启动会开放一些端口(8080,4040),并且机器远程访问需要ssh(22),所以需要关闭防火墙
1 | # 默认清空表中所有链的内容 |
1 | tar -zxvf spark-2.4.4-bin-hadoop2.7.tgz |
server01将会是master,所以只配置这两个
1 | server02 |
1 | # java环境变量 |
启动集群
1 | server01机器启动节点 |
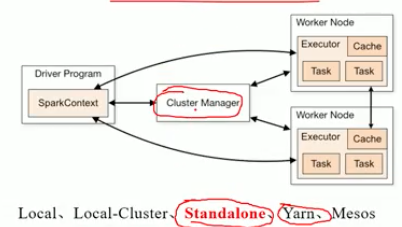
指定master,这样会使用spark集群./bin/spark-shell --master spark://100.80.128.177:7077
不指定,则使用本机器spark./bin/spark-shell
1 | [hadoop@server02 spark-2.4.4-bin-hadoop2.7]$ ./bin/spark-shell |
Nothing:
1 | // List [Nothing]分配给对List [String]的引用。Nothing是String的子类,所以正确 |
在 Scala 中,使用关键词 “var” 声明变量(可以修改),使用关键词 “val” 声明常量(不能修改)。
1 | # 变量(可以修改) |
var VariableName : DataType [= Initial Value]
Scala 中声明变量和常量不一定要指明数据类型,在没有指明数据类型的情况下,其数据类型是通过变量或常量的初始值推断出来的
1 | var myVar = 10; |
1 | val xmax, ymax = 100 // xmax, ymax都声明为100 |
分别有:private,protected,public,没有指定默认是public,
Scala 中的 private 限定符,比 Java 更严格,在嵌套类情况下,外层类甚至不能访问被嵌套类的私有成员
1 | class Outer{ |
(new Inner).f( ) 访问不合法是因为 f 在 Inner 中被声明为 private,而访问不在类 Inner 之内。但在 InnerMost 里访问 f 就没有问题的,因为这个访问包含在 Inner 类之内
在 scala 中,对保护(Protected)成员的访问比 java 更严格一些。因为它只允许保护成员在定义了该成员的的类的子类中被访问。而在java中,用protected关键字修饰的成员,除了定义了该成员的类的子类可以访问,同一个包里的其他类也可以进行访问。
1 | package p { |
Other 对 f 的访问不被允许,因为 other 没有继承自 Super
Scala中,如果没有指定任何的修饰符,则默认为 public。这样的成员在任何地方都可以被访问。
1 | private[x] 或 protected[x] |
这里的x指代某个所属的包、类或单例对象。如果写成private[x],读作”这个成员除了对[…]中的类或[…]中的包中的类及它们的伴生对像可见外,对其它所有类都是private。这种技巧在横跨了若干包的大型项目中非常有用,它允许你定义一些在你项目的若干子包中可见但对于项目外部的客户却始终不可见的东西。
1 | class Hello { |
由于私有变量不能被继承,执行会报错
1 | class Hello { |
重新定义了world的作用域,就可以访问了
1 | package scopeA { |
Scala 为用户提供了一些额外方法,以
帮助用户以更小的粒度对可见性的作用域进行调整。从这一点看,Scala 超过了大多数的语言。Scala 提供了作用域内私有(scoped private)可见性声明和作用域内受保护(scoped protected)可见性声明。请注意,在具有继承关系的情况下,`对类成应用这两类可见性后表现不同。但除此之外,这两类可见性的表现完全一致,因此在同一个作用域内,私有可见性可以和受保护可见性交换使用。
| 符号 | 描述 |
|---|---|
| / | 除号 |
| % | 取余 |
| && | 逻辑与 |
| ` | |
! |
逻辑非 |
>>> |
无符号右移 |
>> |
右移 |
右移与无符号右移区别:
运算符优先级
Scala 运算符
1 | scala> "A"::"B"::Nil |
scala中:: , +:, :+, :::, +++的区别
Scala 中的函数则是一个完整的对象,Scala 中的函数其实就是继承了 Trait 的类的对象。
Scala 中使用 val 语句可以定义函数,def 语句定义方法。
1 | class Test{ |
如果方法没有返回值,可以返回为 Unit,这个类似于 Java 的 void, 实例如下:
1 | object Hello{ |
Scala的解释器在解析函数参数(function arguments)时有两种方式:
在进入函数内部前,传值调用方式就已经将参数表达式的值计算完毕,而传名调用是在函数内部进行参数表达式的值计算的。这就造成了一种现象,每次使用传名调用时,解释器都会计算一次表达式的值
1 | object Test { |
我们也可以通过指定函数参数名,并且不需要按照顺序向函数传递参
1 | object Test { |
Scala 通过在参数的类型之后放一个星号来设置可变参数(可重复的参数)
1 | object Test { |
Scala 可以为函数参数指定默认参数值,使用了默认参数,你在调用函数的过程中可以不需要传递参数,这时函数就会调用它的默认参数值,如果传递了参数,则传递值会取代默认值
1 | object Test { |
Scala 中允许使用高阶函数, 高阶函数可以使用其他函数作为参数
1 | object Test { |
我们可以在 Scala 函数内定义函数,定义在函数内的函数称之为局部函数。
1 | object Test { |
1 | var inc = (x:Int) => x+1 |
Scala 偏应用函数是一种表达式,你不需要提供函数需要的所有参数,只需要提供部分,或不提供所需参数。
1 | import java.util.Date |
闭包出现是因为lexical scope,闭包是由函数和环境组成,Scala应该支持函数作为参数或返回值,这时如果没有闭包,那么函数的free 变量就会出错
闭包源于λ表达式,它的概念核心分为两块,1.上下文环境 2.控制流程。进一步地说,闭包是绑定了自由变量的函数实例。通常来讲,闭包地实现机制是定义一个特殊的数据结构,保存了函数地址指针与闭包创建时的函数的词法环境以及绑定自由变量。对于闭包最好的解释,莫过于《流程的Python》里给出的“它是延伸了作用域的函数,其中包括函数定义体引用,但是不在定义体定义的非全局变量。核心在于闭包能够访问定义体之外定义的非全局变量。
闭包 = 代码 + 用到的非局部变量
1 | scala> var more =1 |
它“捕获”自身的自由变量(more)从而“闭合”该匿名函数
在Scala里“捕获”的是变量本身,而不是变量本身引用的值。
1 | scala> more = 100 |
当然,反过来也是成立的,闭包也可以修改其自由变量
1 | scala> val minusOne = (x:Int) => {more = more - x} |
那么问题来了,如果more这个变量随着程序的运行被修改了很多次,那么闭包会选择哪一个呢?Scala的答案是,闭包被创建时这个变量最新的那个。(根据定义函数的词法作用域计算自由变量)
1 | scala> def Increase(more:Int) = (x:Int) => x + more |
1 | object Test { |
1 | var z:Array[String] = new Array[String](3) |
1 | z(0) = "Runoob"; z(1) = "Baidu"; z(2) = "Google" |
1 | object Closures { |
1 | import scala.Array._ |
Scala 集合分为可变的和不可变的集合
1 | val x = List(1, 3, 4, 5) |
Scala Iterator(迭代器)不是一个集合,它是一种用于访问集合的方法。迭代器 it 的两个基本操作是 next 和 hasNext。
语法:
1 | import scala.util.Random |
1 | # 编写Hello.scala |